Steamgestion - A Data Ingestion Pipeline
December 22, 2022
Gaming industry is currently one of the most prominent industries in the market. The development and popularity of games has been increasing rapidly in the past decade. Of all the factors that determine the popularity of a game, reviews are of paramount importance.
As the online gaming community expands with each passing day, there is more and more data to be processed from the user’s database and therefore, the need for large-scale data ingestion techniques are increasing.

This project aims to analyse Steam reviews dataset and build a data ingestion pipeline using Kubernetes and Docker. The data is ingested from the Steam Reviews dataset which is then cached in Redis and stored in Elasticsearch. The data is then queried from Elasticsearch and rendered using a Flask application.
Architecture
The system uses an asynchronous Flask backend which has been deployed as a service interacting with sQLite for storing
processes followed by an event driven message queue controlled by RabbitMQ. This message queue is also deployed as a service
with an interconnection with Celery workers capable of horizontal pod scaling continuously integrating with Elasticsearch and Redis for data ingestion and data caching. The architecture of the project is shown in the figure below which is a representation of the data pipeline.
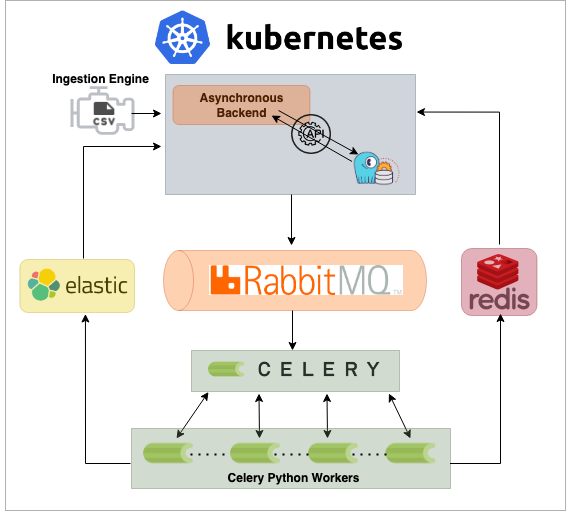
Directory Structure
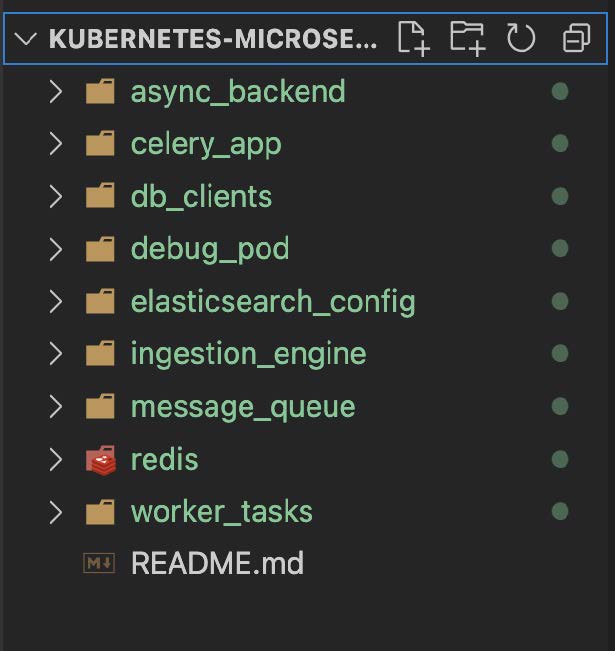
The directory structure of the project is also shown in the figure below which is the exact version as seen on Github repository here.
Installation
Whenever dealing with Kubernetes, one can use micr8s or minikube for kubernetes installation on the base system. MicroK8s is the easiest and fastest way to get Kubernetes up and running. High availability in a Kubernetes cluster, is one of the premiere qualities one should look for when dealing with clusters so as to withstand a failure on any component and continue serving workloads without interruption. Simply following the canonical documentation, one can get started with kubernetes installation by using these commands:
- sudo snap install microk8s –classic
- microk8s status –wait-ready
- microk8s enable dashboard dns registry istio
There are a few python based dependencies which can be installed using: pip3 install -r requirements.txt under the async_backend, celery_app and ingestion_engine directories. These directories have their respective requirements.txt files as shown in the tree structure below:
➜ data-ingestion-pipeline git:(main) ✗ tree
├── async_backend
│ ├── Dockerfile
│ ├── __init__.py
│ ├── database.py
│ ├── deployment_config
│ │ ├── deployment.yaml
│ │ └── service.yaml
│ ├── main.py
│ ├── requirements.txt
│ ├── settings.py
│ ├── static
│ │ ├── main.css
│ │ ├── main.js
│ │ └── reviews.js
│ ├── tasks.py
│ └── templates
│ ├── index.html
│ └── show.html
├── celery_app
│ ├── Dockerfile
│ ├── celery-hpa.yaml
│ ├── deployment.yaml
│ ├── main.py
│ └── requirements.txt
└── ingestion_engine
├── ingestion_engine.py
└── requirements.txt
Aliasing

Aliasing of microk8s kubectl to kcdev is also done for using kubernetes as a short form for convenience which can be done by adding an alias in the bashrc/zshrc profile which can be done by:
- echo "alias kcdev='microk8s kubectl'" >> ~/.zshrc
or one can also use vim or nano to edit the ~/.zshrc file as shown below:
- vim ~/.zshrc
And then add the following line to the file:
- alias kcdev='microk8s kubectl'
Yaml Files
The YAML files describe the desired state of the resources, such as pods, deployments, services, and more. Kubernetes uses these files to deploy resources to the cluster and manage them accordingly.

We will use a set of commands to deploy and serve the backend, elasticsearch, rabbitmq and redis environments using yaml configuration files to start the kubernetes environment. The commands are as follows:
- elasticsearch-setup-passwords auto
- kcdev apply -f async_backend/deployment_config/service.yaml
- kcdev apply -f async_backend/deployment_config/deployment.yaml
- kcdev apply -f debug_pod/debug_pod.yaml
- kcdev apply -f elasticsearch_config/elasticsearch_deployment.yaml
- kcdev apply -f elasticsearch_config/elasticsearch_pv.yaml
- kcdev apply -f elasticsearch_config/elasticsearch_service.yaml
- kcdev apply -f message_queue/rabbitmq_deployment.yaml
- kcdev apply -f message_queue/rabbitmq_service.yaml
- kcdev apply -f redis/redis_pv.yaml
- kcdev apply -f redis/redis_deployment.yaml
- kcdev apply -f redis/redis_service.yaml
Working
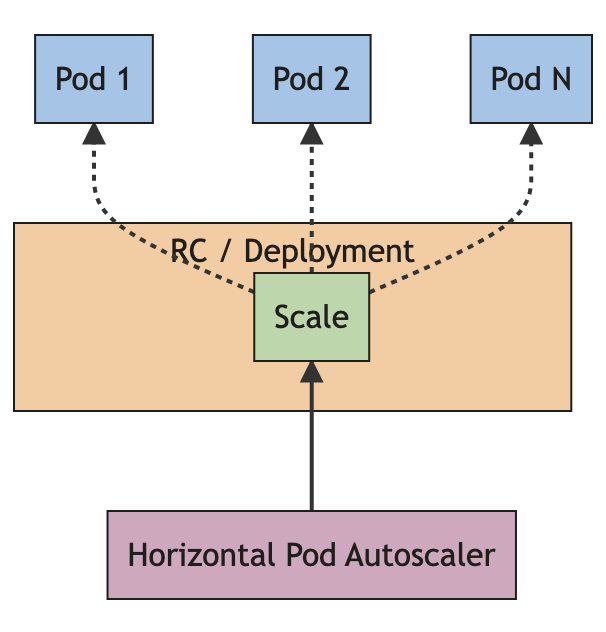
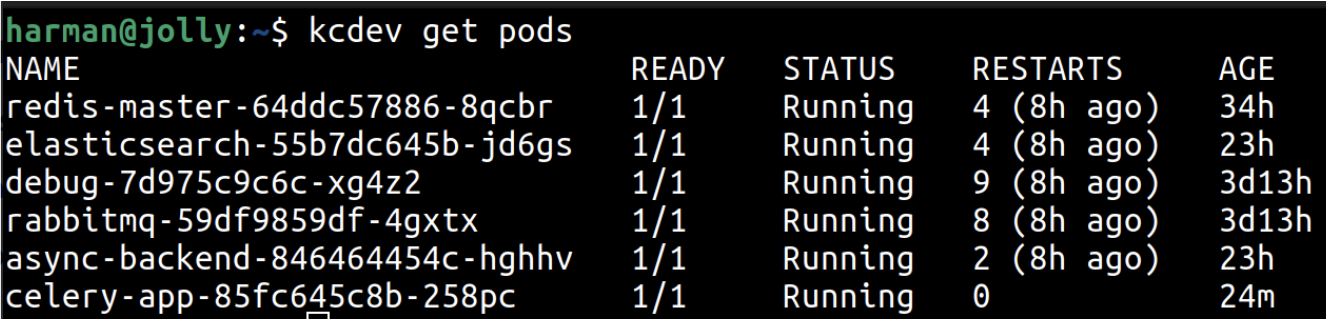
Using Kubernetes, we have setup 6 microservice pods which can be seen in the firgure below. These microservices run in an even driven architecture which are given persistent volumes for claiming the resources. In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource (such as a Deployment), with the aim of automatically scaling the workload to match demand. Horizontal scaling means that, the response to increased load is to deploy more pods. If the load decreases, and the number of Pods is above the configured minimum, the HorizontalPodAutoscaler instructs the workload resource to scale back down.
The visual representation of the pods that are already running for the workload are shown in the figure below.
Celery Workers
Celery is a simple, flexible, and reliable distributed system to process vast amounts of messages and tasks, while providing operations with the tools required to maintain such a system. There’s a huge variety between those tasks: some of them can run for seconds while others can take hours, depending on the data (size) being processed and the operation type (read/write). When a task is published, Celery adds a message to the RabbitMQ queue. In our case, each worker consumes from a dedicated queue for simplicity and ease to auto-scale.
Persistent Volumes
A PersistentVolume (PV) as shown in the figure below is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. It is a resource in the cluster just like a node is a cluster resource.

A PersistentVolumeClaim (PVC) as shown in the figure below is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory).

Results
Using port forwarding to render the results on a Flask application, one can show the processes and ids of celery workers running concurrently and scaling at the same time. In the figure below, the process ids are seen on a scaffoled flask template.
For quering the Steam Reviews for exploration, relevant columns are extracted such as language of review, the review itself, game name and whether it is recommended or not. In the figure below, the process ids are seen on a scaffoled flask template.

Acknowledgements & Feedback
I would like to express my gratitude to Shlok Walia in helping me out during the course of this project. He has been a constant guide throughtout this project and his meticulous attention to detail greatly enhanced the quality and functionality of the final product.
I would also love to receive suggestions or any feedback for this writing. It has been written as per my understanding and the learnings I kindled during my journey in this project. I hope you find it useful and easy to understand.